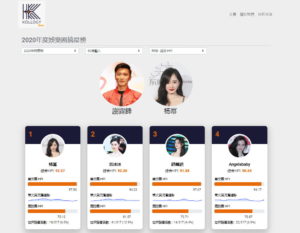
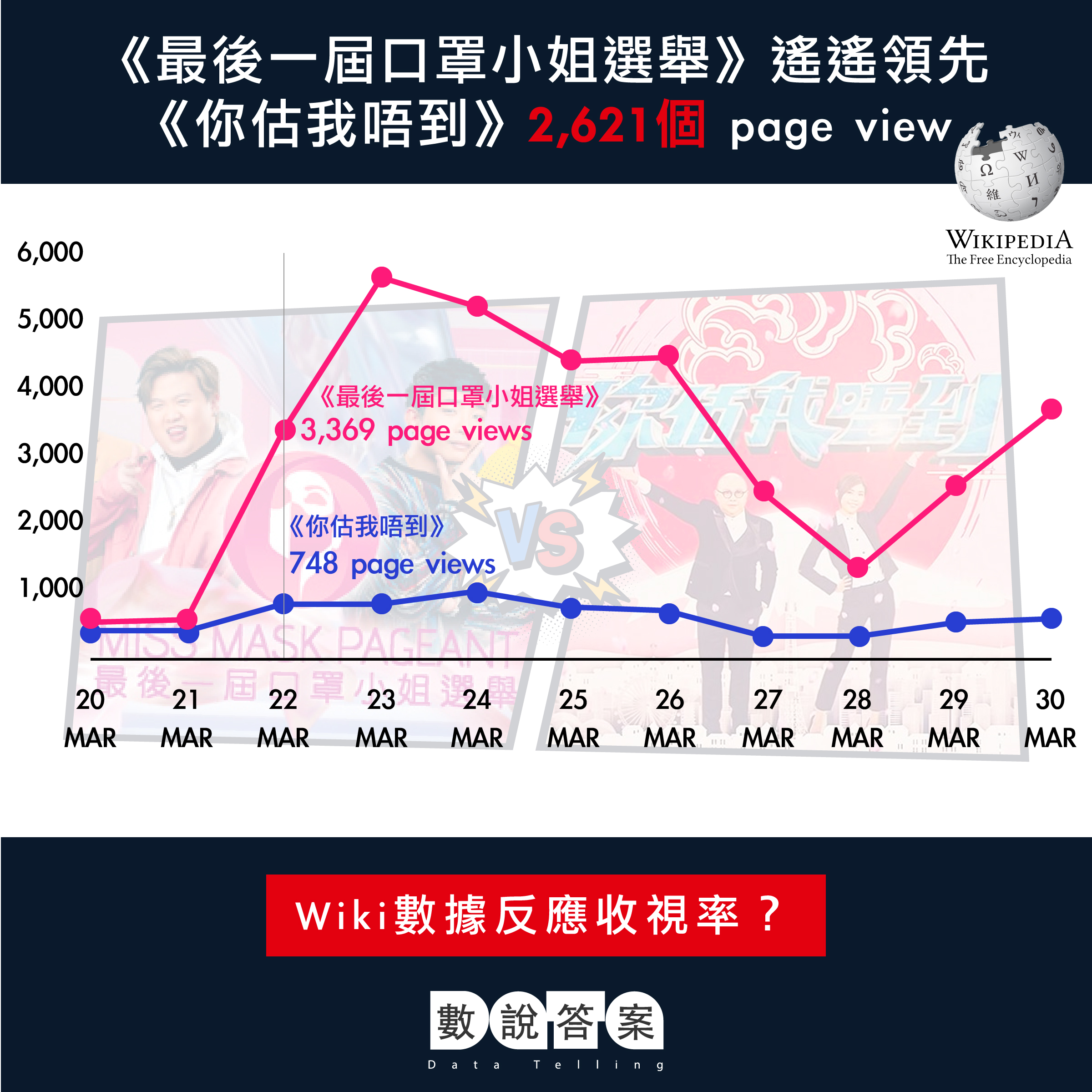
原文:http://startupbeat.hkej.com/?p=101160
美國《時代》周刊每年公布世界上最具影響力的100名公眾人物「時代百大人物」(TIME 100)。 在互聯網數據產業並未發達的年代,評選模式多採用讀者投票方式進行,或者由幾個德高望重的評委決定一切。隨着技術不斷進步,通過數據採集來建立模型解決問題的方式逐漸被大眾認可,例如谷歌的成名作Page Rank、Netflix劇集的人氣排行榜,都已成為人們生活一部分。
筆者在2020年身處香港疫情期間,除了完成拙作《數循環》之外,因為受到巴拉巴西(Albert-László Barabási)著作《成功竟然有公式:大數據科學揭露成功的秘訣》(The Formula: The Universal Laws of Success)的啟發,一鼓作氣也完成了一個比較科學化的演算項目。
巴拉巴西認為人的能力雖是有限,但成功可以無限;成功的定義更多來自社會對你的認同,尤其是進入二十一世紀之後,網絡影響力已經成為了成功的重要因素。作為教授,他的學生身體力行,研究出利用維基百科的數據,建立一個為名人排名的算法。筆者受到以上的啟發,希望做一個更聚焦於華人影響力的指數(Historical Popularity Index)。

經過半年籌備,得到阿里巴巴商學院研究生及熱愛大數據的朋友支持,起動一個名為「擇星榜」(www.kollogy.com)的項目。
「擇星榜1.0」目的是通過維基百科的數據建立一個合理高效、穩定及可解釋的華人影響力排行榜的模型。模型包括兩部分︰漢語語系及非漢語語系對中國公眾人物影響力的不同算法,排列出一個較客觀的、綜合華人視角及全球視角的人物影響力排名。
冀為科學普及化出力
基於維基百科在谷歌搜尋的排名優勢,維基的瀏覽量與人物的被關注度有強關聯關係。「擇星榜」的算法利用了維基百科開放數據作為基礎,選擇了瀏覽量、閱讀深度和時序因素作為主要變量,同時參考了名人的出生年份、編輯次數及語言版本的多寡。因為模型中使用了不同指標,我們要對指標之間進行結構性調整,以減少模型中不同指標之間的相互影響及加強其平穩性。然而,任何的算法都需要時間去沉澱及不斷改進,「擇星榜」也不例外,必然有很多地方有待提升。
有朋友問我為什麼要浪費時間去做一些不賺錢的事情,但筆者一直秉持一個理念:未來數據將成為生活中的一部分,每個人都需要認識大數據,因此推動大數據科學普及化是有必要的。